
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- KT에이블스쿨 #에이블 #DX #3기
- randomsearch
- kt에이블 스쿨 #kt #공모전 #DX 후기 # DX 3기 # kt 에이블스쿨 DX 3기 # kt 에이블스쿨 3기
- 머신러닝 #ML #copysheet # ML copysheet #머신러닝 copysheet
- 파이썬 #python #함수 #내장함수 #예외처리
- Python #파이썬 #판다스 #pandas #선형보간법 #결측치처리
- ADsP #데이터준전문가
- 파이썬 #python #numpy #array #배열 #인덱싱 #슬라이싱
- 파이썬 #python #리스트 #리스트 컴프리헨션 #딕셔너리 #메소드
- batch normalization
- KT에이블스쿨 #aice합격후기 #aice associate # aivle합격
- Auto ML
- python #pandas #판다스 #파이썬 #DataFrame #데이터탐색 #데이터 조회 #데이터 집계 #jupyter lab #jupyter notebook
- 32회 #ADsP #데이터분석준전문가
- 에이블후기
- IT 인프라 #서브넷 #7계층 #OSI #TCP #IT Infra
- python #파이썬 #판다스 #pandas #가변수화 #get_dummies #범주화
- ADsP #데이터분석준전문가
- 파이썬 #python #DataFrame #pandas #판다스
- Image Data Augmentation #
- 하이퍼파라미터 최적화
- KT #kt #kt에이블스쿨 #DX #kt aivle 3기 # kt aivle dx # DX후기
- Softmax
- 파이썬 #python #class
- 파이썬 # python # 이변량분석 # 단변량분석 # 시각화 # 수치화
- KT에이블스쿨 3기 #DX과정 #인적성 #
- KT에이블스쿨 #DX #DX 3기 #후기 #기자단 #에이블 기자단
- argmax #다중분류
- cnn #keras #딥러닝 # EarlyStopping #
- KT에이블스쿨
- Today
- Total
파이썬 하는 파이리
Python_판다스(pandas)_(2) 본문
https://www.kaggle.com/datasets/jr2ngb/superstore-data
superstore_data
retail sales
www.kaggle.com
1. 판다스로 csv파일 불러오고 조작하기
1-1. 데이터파일은 캐글에 올라와있는 superstore 데이터를 활용.
[데이터 설명]
-4 년 동안 글로벌 슈퍼마켓의 소매 데이터 세트
[columns설명]
shipmode: 배송모드
segment : 고객군
country : 나라
city :도시
state : 주
postal code :우편번호
region : 지역방위
category :제품 카테고리
sub-category : 하위카테고리
sales :판매액
quantity : 수량
discount :할인율
profit : 이익
1-2. 항상 먼저 확인할 메소드
head(): 상위 데이터 확인
tail(): 하위 데이터 확인
shape: 데이터프레임 크기
index: 인덱스 정보 확인
values: 값 정보 확인
columns: 열 정보 확인
dtypes: 열 자료형 확인
info(): 열에 대한 상세한 정보 확인
describe(): 기초통계정보 확인
1-3. 파일 불러오기
# df =pd.read_csv('파일경로',encoding='필요한 형식')
store = pd.read_csv('C:\\Users\\User\\data\\SampleSuperstore.csv',encoding='CP949')
store.head()
#파일경로를 변수로 선언하고 넣어도 됨
# path='C:\\Users\\User\\data\\SampleSuperstore.csv',encoding='CP949'
# store = pd.read_csv(path,encoding='CP949')
2.데이터 탐색하기
#데이터 형태 확인
store.shape
# 실행결과
#(9994, 13)
#데이터 정보
store.info()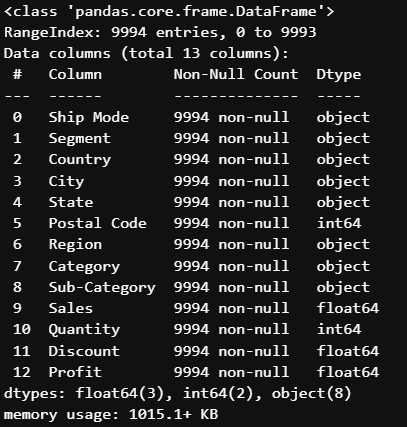
#기술통계확인
store.describe()
어떤 배송형태가 가장 많을까? => value_count() 활용
#어떤 배송모드가 가장 많은지
store['Ship Mode'].value_counts()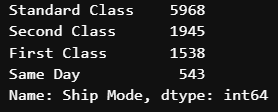
#Profit이 높은순으로 내림차순 정렬
#ascending =True는 오름차순 정렬
pratice = store.sort_values(by='Profit',ascending=False)
pratice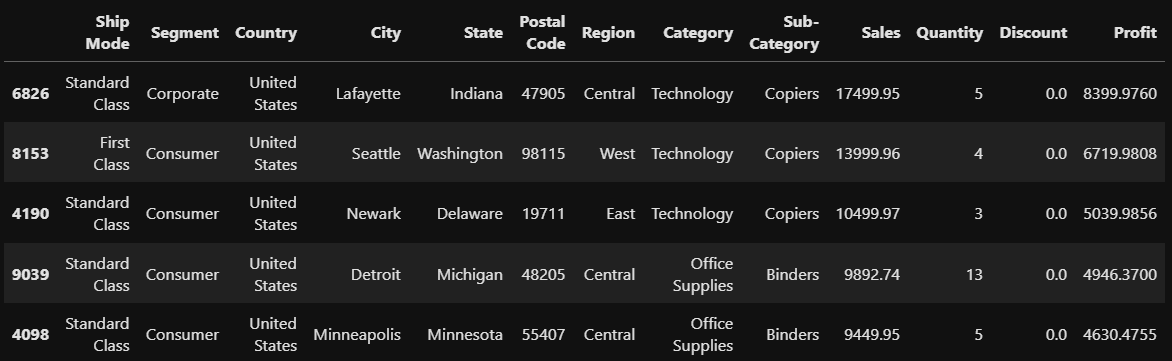
정렬하면서 인덱스가 무의미하게 섞였기 때문에 초기화 시켜주기
#인덱스 초기화
pratice.reset_index(drop=True, inplace=True) #drop=True는 기존 인덱스 제거
pratice.head()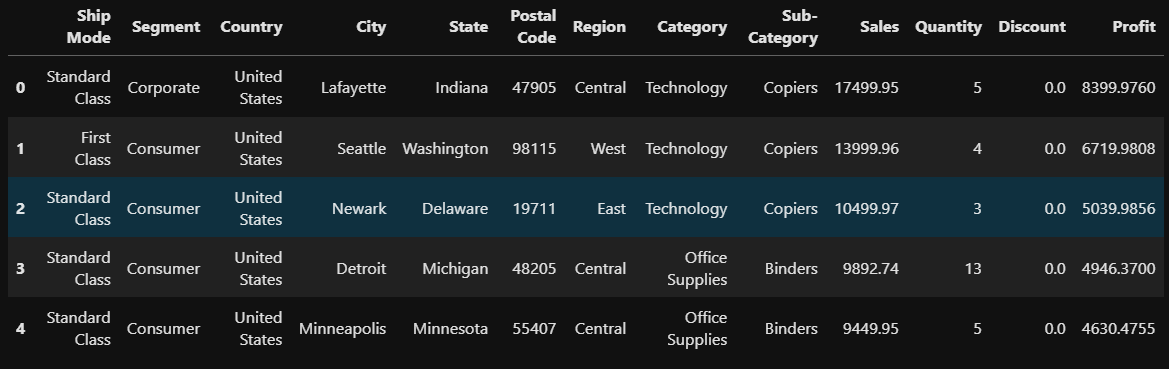
어떤 고객군이 가장 많은지 궁금하다 => 최빈값을 활용
# 최빈값 메소드 mode()
store['Segment'].mode()
총 수량의 합계가 궁금하다 => sum()
#열기준 합을 구해야 한다 (전체 행을 더하라)=>axis=0
store[['Quantity']].sum(axis=0)
그렇다면 매출평균이 어떻게 될까? 기술통계에서 확인할 수 있지만 mean 매소드를 통해서 확인도 가능
#superstore 매출평균
store[['Sales']].mean()
3. 데이터 조회
특정 열과 행을 조회하고 싶을 수 있다. 위에서 이미 사용했지만 .loc라는 메소드로 다양하게 접근해본다.
#열 조회
#df.loc[ : , [열 이름1, 열 이름2,...]]
#열은 생략가능 행은 생략불가능
#df[[열 이름1, 열 이름2,...]] => 일반적인 구문
store.loc[:,['City','State']]
store[['City','State']]
범위를 지정할때는 loc를 꼭 사용하자
#범위를 지정할땐 loc 쓰자
store.loc[ :, 'City':'State']
특정조건을 만족하는 데이터만 뽑는것도 가능하다. 매출액이 평균이상인 것들만 조회해보자.
#df.loc[조건] 형태로 조건을 지정해 조건에 만족하는 데이터만 조회
# 매출액이 평균이상인것들만 조회
sales_mean = store['Sales'].mean()
store.loc[(store['Sales'] >= sales_mean)].head()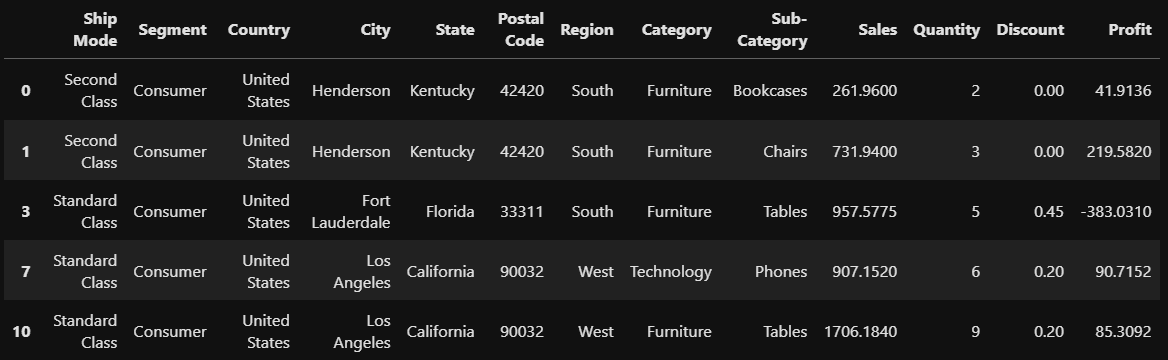
#조건에 맞는 하나의 열만 조회
df = store.loc[(store['Sales'] >= sales_mean),['City']]
df
그렇다면 매출액이 평균이상인 city 중 어디가 제일 많을까? =>vlaue_count() 사용
#매출액이 평균이상인 city는 뉴욕이 젤 많다
df.value_counts()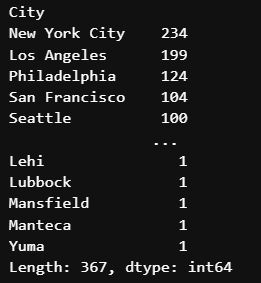
isin 구문
isin([값1, 값2,..., 값n]): 값1 또는 값2 또는...값n인 데이터만 조회
#city중 뉴욕과 LA가 포함된 데이터들만 조회
store.loc[ store['City'].isin(['New York City',"Los Angels"]) ]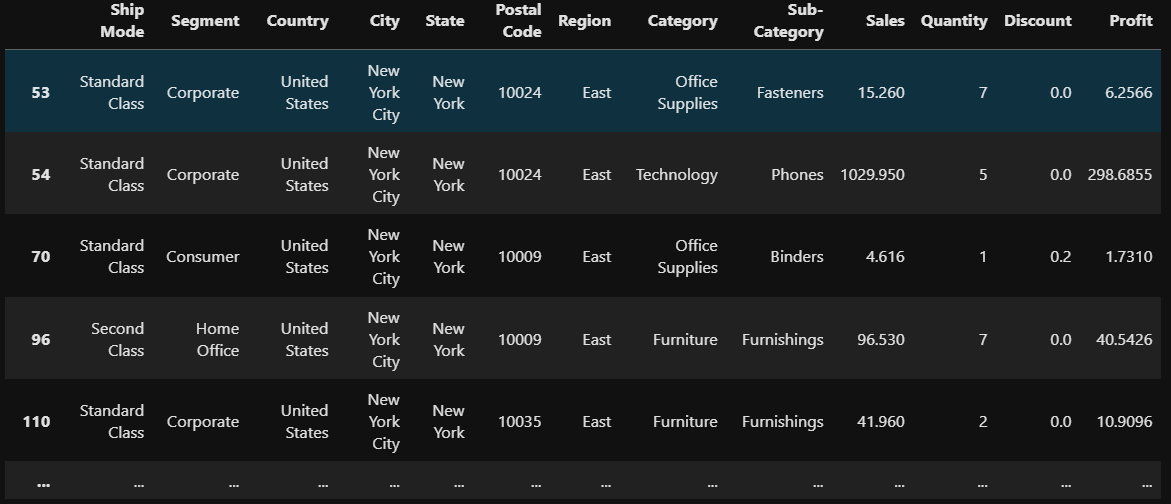
4. 데이터 집계
-범주값을 기준으로 연속값을 집계
-as_index=False를 설정하면 행 번호를 기반으로 한 정수 값이 인덱스로 설정
-합,평균,중앙값,표준편차 등등 을 집계
# 도시별 매출액, 이익의 합
store.groupby(by='City', as_index=False)[ ['Sales','Profit'] ].sum()
# 도시별 매출액, 이익의 중앙값
store.groupby(by='City', as_index=False)[ ['Sales','Profit'] ].median()
# 도시별 매출액, 이익의 표준편차
store.groupby(by='City', as_index=False)[ ['Sales','Profit'] ].std()
# 도시별 매출액, 이익의 평균
store.groupby(by='City', as_index=False)[ ['Sales','Profit'] ].mean()
# 도시별 매출액, 이익의 최대값
store.groupby(by='City', as_index=False)[ ['Sales','Profit'] ].max()
# 집계 기준열을 여럿 설정가능
# .sum()앞에 아무열도 지정하지 않으면 기준열 이외의 모든열에 대한 집계가 이루어짐
store.groupby(by=['City','State'], as_index=False).sum()
다음은 시각화도 해보면서 데이터탐색을 더 해볼 예정이다.
'프로그래밍 > python' 카테고리의 다른 글
| Python_판다스(pandas)_(4) (5) | 2023.02.25 |
|---|---|
| PYthon_판다스(pandas)_(3) (0) | 2023.02.25 |
| Python_판다스(pandas)_(1) (0) | 2023.02.11 |
| Python_배열(numpy) (0) | 2023.02.11 |
| Python_함수 (0) | 2023.02.07 |



