
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Image Data Augmentation #
- kt에이블 스쿨 #kt #공모전 #DX 후기 # DX 3기 # kt 에이블스쿨 DX 3기 # kt 에이블스쿨 3기
- Python #파이썬 #판다스 #pandas #선형보간법 #결측치처리
- 32회 #ADsP #데이터분석준전문가
- 파이썬 #python #함수 #내장함수 #예외처리
- KT에이블스쿨 #aice합격후기 #aice associate # aivle합격
- 머신러닝 #ML #copysheet # ML copysheet #머신러닝 copysheet
- batch normalization
- python #pandas #판다스 #파이썬 #DataFrame #데이터탐색 #데이터 조회 #데이터 집계 #jupyter lab #jupyter notebook
- Auto ML
- 파이썬 #python #DataFrame #pandas #판다스
- KT에이블스쿨 3기 #DX과정 #인적성 #
- Softmax
- KT에이블스쿨 #DX #DX 3기 #후기 #기자단 #에이블 기자단
- randomsearch
- cnn #keras #딥러닝 # EarlyStopping #
- 파이썬 #python #numpy #array #배열 #인덱싱 #슬라이싱
- 파이썬 #python #리스트 #리스트 컴프리헨션 #딕셔너리 #메소드
- 에이블후기
- 파이썬 # python # 이변량분석 # 단변량분석 # 시각화 # 수치화
- argmax #다중분류
- 하이퍼파라미터 최적화
- KT에이블스쿨 #에이블 #DX #3기
- KT #kt #kt에이블스쿨 #DX #kt aivle 3기 # kt aivle dx # DX후기
- ADsP #데이터분석준전문가
- ADsP #데이터준전문가
- python #파이썬 #판다스 #pandas #가변수화 #get_dummies #범주화
- 파이썬 #python #class
- IT 인프라 #서브넷 #7계층 #OSI #TCP #IT Infra
- KT에이블스쿨
Archives
- Today
- Total
파이썬 하는 파이리
Python_판다스(pandas)_(4) 본문
1.결측치(NaN)
- 정확한 데이터 준비를 위해 누락된 데이터나 중복 데이터를 제거하는 전처리 작업이 필요
- 결측치는 제거 혹은 대체를 해줘야한다.
- 무조건적인 제거는 X
#데이터 불러오기
air = pd.read_csv('https://raw.githubusercontent.com/Jangrae/csv/master/airquality.csv')
air.head()
[데이터 설명]
- Ozone: 오존 농도
- Solar.R: 태양복사량
- Wind: 풍속
- Temp: 기온
- Month: 월
- Day: 일
1-1. 결측치 찾기
- isnull() :결측치면 True, 유효값은 False를 반환
- notnull() :결측치면 False, 유효한 값이면 True를 반환합니다.
- isnull() 대신 isna(), notnull() 대신 notna() 메소드도 가능.
- df.isna().sum() : 열의 결측치 개수 확인 => 자주사용
# 열의 결측치 개수 확인
air.isnull().sum()
1-2. 결측치 제거
- dropna() : 결측치가 있는 열이나 행을 제거.
- inplace=True 옵션을 지정해야 해당 df에 반영
- axis 옵션으로 행을 제거할 지 열을 제거할 지 선택.
- axis=0: 행 제거(기본값)
- axis=1: 열 제거
# 결측치 제거(행) -> 결측치가 있는 행 제거
#테스트용 df복사
air_test = air.copy()
air_test.dropna(axis=0, inplace=True)
air_test.isna().sum()
- 특정 열에 결측치 있는 행 제거
- subset() 함수
#테스트용 복사
air_1=air.copy()
# 오존컬럼 nan값 제거
air_1.dropna(subset=['Ozone'], axis=0, inplace=True)
air_1.isna().sum()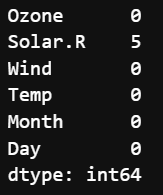
# 결측치 제거 (열) => 컬럼
# 데이터프레임 복사
air_test2 = air.copy()
# 결측치가 있는 열 제거
air_test2.dropna(axis=1, inplace=True)
# 확인
air_test2.isna().sum()
1-3. 결측치 대체
- fillna() 메소드 사용
#
air_test3 = air.copy()
# Ozone 평균 구하기
mean_Ozone = air_test3['Ozone'].mean()
# 결측치를 평균값으로 채우기
air_test3['Ozone'].fillna(mean_Ozone, inplace=True)
# 확인
air_test3.isna().sum()
# Solar.R 열의 누락된 값을 0으로 채우기
air_test['Solar.R'].fillna(0, inplace=True)
# 확인
air_test.isna().sum()
- fillna(method='ffill') & fillna(method='bfill)
- 직전 행의 값 또는 뒤의 행의 값으로 채우는 방법
#테스트 데이터 복사
air_test4 = air.copy()
# Ozone 컬럼의 Nan 값을 바로 앞의 값으로 채우기
air_test4['Ozone'].fillna(method='ffill', inplace=True)
# Solar.R 컬럼의 Nan 값을 바로 뒤의 값으로 채우기
air_test4['Solar.R'].fillna(method='bfill', inplace=True)
# 확인
air_test4.isna().sum()
- 선형보간법
- 1차원 직선상에서 두 점의 값이 주어졌을 때 그 사이의 값을 추정하기 위해 가상의 직선이 있다고 가정하고 직선 거리에 따라 선형적으로 계산
- 비례정도를 통해 , 앞 뒤 값으로 추정한다고 생각
- interpolate() 메소드 사용
# 테스트 데이터 복사
air_test5 = air.copy()
# 선형보간법
# 시계열에서 method='vlaue' 등 여러가지가 존재 한다 여기선 linear사용
air_test['Ozone'].interpolate(method='linear', inplace=True)
air_test['Solar.R'].interpolate(method='linear', inplace=True)
# 확인
air_test.isna().sum()
※ 데이터 전처리
- 시계열 데이터 사용시 plot을 사용해 그래프의 개형을 보고
- 이상치가 있는곳을 간략히 확인 후 제거
- 이상치는 잘못된 데이터값, 중복데이터 등이 존재
- df.drop_duplicates(inplace = True, keep='first') => 중복값 제거하기
2. 데이터프레임 합치기
- concat() 함수를 사용해 인덱스 값을 기준으로 두 데이터프레임을 가로 또는 세로로 합칠 수 있음
- axis=1 :열기준(가로로 합치기) axis=0 :행기준(세로로 합치기)-디폴트
- join=outer(다 포함 nan값 생김)-디폴트
- join=inner (매핑되지 않는 행은 제외)
<가로로 합치기>
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/seoul_pop_h01.csv'
df01 = pd.read_csv(path, index_col='year')
df01.index.name = None
# 확인
df01.head(10)
# 서울 인구정보 읽어오기 #2
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/seoul_pop_h02.csv'
df02 = pd.read_csv(path, index_col='year')
df02.index.name = None
# 확인
df02.head(10)
# 모든 헹 합치기 (기본값 outer)
pop = pd.concat([df01,df02],axis=1)
# 확인
df.head(10)
# 모든 헹 합치기 inner로 조인
pop2 = pd.concat([df01,df02],axis=1, join='inner')
# 확인
pop.head(10)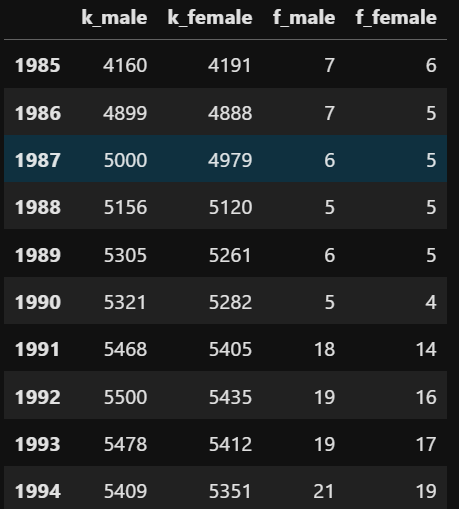
<세로로 합치기>
# 서울 인구정보 읽어오기 #1
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/seoul_pop_v01.csv'
pop01 = pd.read_csv(path)
# 서울 인구정보 읽어오기 #2
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/seoul_pop_v02.csv'
pop02 = pd.read_csv(path)

# axis=0이 디폴트 따라서 생략가능
pop = pd.concat([pop01,pop02],axis=0)
#인덱스 초기화
#세로로 합치면 인덱스가 중복됨
pop.reset_index(drop=True, inplace=True)
- merge()함수로 합칠 수 있음 => 지정한 키 값을 기준으로(컬럼)
- pop = pd.merge(df1, df2, on='year', how='inner')
- 같은 이름의 열이 존재하면 on옵션 없어도 그 기준으로 조인
- inner가 디폴트
pop = pd.merge(pop01, pop02, on='year', how='outer')
# 확인
pop.head(10)
- 기본적인 판다스의 정리는 이번글로 마무리
- 다음은 본격적인 시각화와 데이터분석에 대해 포스팅(통계)
- 또한 Pandascheatsheet을 만들어서 그때 그때 필요한 판다스 메소드와 함수를 사용하기.
'프로그래밍 > python' 카테고리의 다른 글
| Python_데이터 분석 (0) | 2023.03.26 |
|---|---|
| Python_ 클래스 (class) (0) | 2023.03.26 |
| PYthon_판다스(pandas)_(3) (0) | 2023.02.25 |
| Python_판다스(pandas)_(2) (0) | 2023.02.11 |
| Python_판다스(pandas)_(1) (0) | 2023.02.11 |
'프로그래밍/python' Related Articles
more



Comments